今天来总结一下树和图的解题套路。此篇包括:
构造树
树的遍历 (递归 & 迭代)
网格遍历
并查集 (Union Find)
递归
回溯 (治理分支污染)
树
构造树 1 2 3 4 5 6 TreeNode root = new TreeNode(value); root.left = recursion(left); root.right = recursion(right); return root;
树的遍历 (递归 & 迭代)
遍历所有节点, 打印输出 (Link)
总结:
**BFS 节省时间 **, DFS 节省空间
剪枝 : 不符合条件的直接结束,以免 TLE
BFS 解决最短路 ,DFS 解决连通性
BFS 每层遍历。本质还是和 DFS-前序 很像,都是遵循 root - left - right 的顺序。
迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public void bfs (TreeNode root) if (root == null ) return root; Queue<TreeNode> q = new LinkedList<>(); q.offer(root); while (!q.isEmpty()) { for (int i = q.size(); i > 0 ; ++i) { TreeNode node = q.poll(); System.out.print(node.val); if (node.left != null ) q.offer(node.left); if (node.right != null ) q.offer(node.right); } } return ; }
递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public void bfs (TreeNode root) int d = depth(root); for (int level = 0 ; level < d; ++level) printPath(root, level); } private void printPath (TreeNode root, int level) if (root == null ) return root; if (level == 0 ) System.out.print(root.val); else { printPath(root.left, level - 1 ); printPath(root.right, level - 1 ); } } private int depth (TreeNode root) if (root == null ) return 0 ; int l = depth(root.left); int r = depth(root.right); return Math.max(l, r) + 1 ; }
DFS (前序) 顺序: root - left - right
递归
1 2 3 4 5 6 7 8 public void dfs (TreeNode root) if (root == null ) return root; System.out.print(root.val); dfs(root.left); dfs(root.right); }
迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public void dfs (TreeNode root) if (root == null return root); Stack<TreeNode> s = new Stack<>(); s.push(root); while (!s.isEmpty()) { TreeNode node = s.pop(); System.out.print(node.val); if (node.right != null ) s.push(node.right); if (node.left != null ) s.push(node.left); } return ; }
后序 顺序: left - right - root
递归
1 2 3 4 5 6 7 8 public void postorder (TreeNode root) if (root == null ) return root; postorder(root.left); postorder(root.right); System.out.print(root.val); }
迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void postorder (TreeNode root) if (root == null ) return root; Stack<TreeNode> path = new Stack<>(); Stack<TreeNode> s = new Stack<>(); s.push(root); while (!s.isEmpty()) { TreeNode node = s.pop(); path.push(node); if (node.left != null ) s.push(node.left); if (node.right != null ) s.push(node.right); } while (!path.isEmpty()) System.out.print(path.pop()); return ; }
中序 顺序: left - root - right
递归
1 2 3 4 5 6 7 8 public void inorder (TreeNode root) if (root == null ) return root; inorder(root.left); System.out.print(root.val); inorder(root.right); }
迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public void inorder (TreeNode root) if (root == null ) return root; Stack<TreeNode> s = new Stack<>(); while (!s.isEmpty() || root != null ) { if (root != null ) { s.push(root); root = root.left; } else { root = s.pop(); System.out.print(root.val); root = root.right; } } return ; }
图
网格遍历
网格类问题 DFS 通用思路
和二叉树的 DFS 类比。
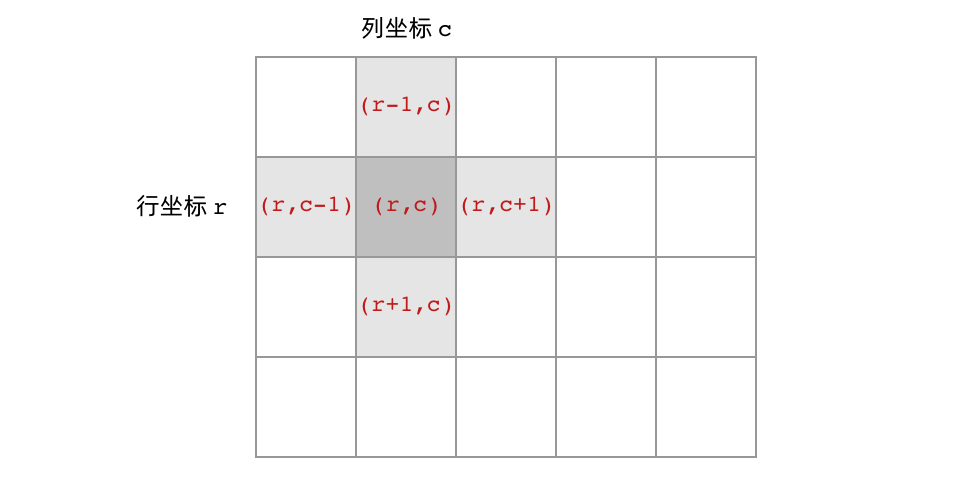
首先,网格结构中的格子有多少相邻结点?答案是上下左右四个。对于格子 (r, c) 来说(r 和 c 分别代表行坐标和列坐标),四个相邻的格子分别是 (r-1, c)、(r+1, c)、(r, c-1)、(r, c+1)。换句话说,**网格结构是「四叉」的 **。
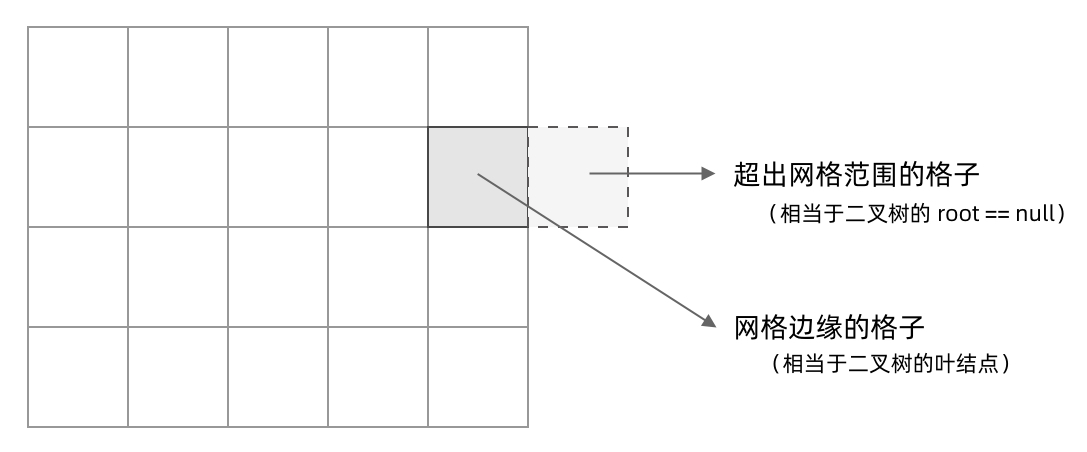
网格 DFS 中的 base case :
不需要继续遍历、grid[r][c] 会出现数组下标越界异常的格子,也就是那些超出网格范围的格子。
网格结构的 DFS 与二叉树的 DFS 最大的不同之处在于,遍历中可能遇到遍历过的结点。 (因为图是连通的)
避免重复遍历: 标记已经遍历过的格子
每走过一个陆地格子,就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。
0 —— 海洋格子
1 —— 陆地格子(未遍历过)
2 —— 陆地格子(已遍历过)
框架代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void dfs (int [][] grid, int r, int c) if (!inArea(grid, r, c)) return ; if (grid[r][c] != 1 ) return ; grid[r][c] = 2 ; dfs(grid, r - 1 , c); dfs(grid, r + 1 , c); dfs(grid, r, c - 1 ); dfs(grid, r, c + 1 ); } public boolean inArea (int [][] grid, int r, int c) return 0 <= r && r < grid.length; && 0 <= c && c < grid[0 ].length; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public int numIslands (char [][] grid) int count = 0 ; for (int i = 0 ; i < grid.length; ++i) { for (int j = 0 ; j < grid[0 ].length; j++) { if (grid[i][j] == '1' ) { count++; dfs(grid, i, j); } } } return count; } private void dfs (char [][] grid, int i, int j) if (i < 0 || j < 0 || i >= grid.length || j >= grid[0 ].length || grid[i][j] != '1' ) return ; grid[i][j] = 2 ; dfs(grid, i + 1 , j); dfs(grid, i, j + 1 ); dfs(grid, i - 1 , j); dfs(grid, i, j - 1 ); }
并查集
LC Link
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class UnionFind private Map<Integer,Integer> father; public UnionFind () father = new HashMap<Integer,Integer>(); } public void add (int x) if (!father.containsKey(x)) father.put(x, null ); } public void merge (int x, int y) int rootX = find(x); int rootY = find(y); if (rootX != rootY) father.put(rootX,rootY); } public int find (int x) int root = x; while (father.get(root) != null ) root = father.get(root); while (x != root){ int original_father = father.get(x); father.put(x,root); x = original_father; } return root; } public boolean isConnected (int x, int y) return find(x) == find(y); } }
题目分析:
考察连通分量的数目,所以我们要在模板中额外添加一个变量去跟踪集合的数量 (有多少棵树)。
添加的时候把集合数量加一
合并的时候让集合数量减一
用并查集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 class Solution public int findCircleNum (int [][] isConnected) UnionFind uf = new UnionFind(); for (int i = 0 ; i < isConnected.length; ++i){ uf.add(i); for (int j = 0 ; j < i; ++j) if (isConnected[i][j] == 1 ) uf.merge(i,j); } return uf.getNumOfSets(); } } class UnionFind private Map<Integer,Integer> father; private int numOfSets; public UnionFind () father = new HashMap<Integer,Integer>(); numOfSets = 0 } public int getNumOfSets () return numOfSets; } public void add (int x) if (!father.containsKey(x)) { father.put(x, null ); numOfSets++; } } public void merge (int x, int y) int rootX = find(x); int rootY = find(y); if (rootX != rootY) { father.put(rootX,rootY); numOfSets--; } } public int find (int x) int root = x; while (father.get(root) != null ) root = father.get(root); while (x != root){ int original_father = father.get(x); father.put(x,root); x = original_father; } return root; } public boolean isConnected (int x, int y) return find(x) == find(y); } }
递归 & 回溯
递归
两篇文章
Link 1
Link 2
简单总结:
分析问题我们需要采用自上而下 的思维,而解决问题有时候采用自下而上 的方式能让算法性能得到极大提升
e.g. Climbing Stairs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public int f (int n) if (n == 1 ) return 1 ; if (n == 2 ) return 2 ; int result = 0 ; int pre = 1 ; int next = 2 ; for (int i = 3 ; i < n + 1 ; i ++) { result = pre + next; pre = next; next = result; } return result; }
改造后的时间复杂度是 O(n), 而由于我们在计算过程中只定义了两个变量(pre,next),所以空间复杂度是O(1)
回溯 治理分支污染 防止分支污染: ( e.g. 3 Sum )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private void combSum (List<Integer> cur, int sums[], int target) if (target == 0 ) return ; for (int i = 0 ; i < sums.length; i++) { if (target < sums[i]) continue ; List<Integer> list = new ArrayList<>(cur); list.add(sums[i]); combSum(list, sums, target - sums[i]); } return ; }
但每次都重新创建数据,运行效率很差。第二种方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private void combSum (List<Integer> cur, int sums[], int target) if (target == 0 ) return ; for (int i = 0 ; i < sums.length; i++) { if (target < sums[i]) continue ; cur.add(sums[i]); combSum(list, sums, target - sums[i]); cur.remove(cur.size() - 1 ); } return ; }
回溯实质上是一种暴力算法 ,所以很多时候我们需要 剪枝操作
关于N皇后:
https://cloud.tencent.com/developer/article/1424758